Exploit Headless Chrome
背景
Chrome M59引入了 Headless Chrome,至此可以在无GUI的环境下使用Chrome,极大的方便了自动化测试工作,也可以用于预览服务,或者网络爬虫。
前端并不是我的强项,我在上网冲浪的时候发现一个很有趣的现象:
- 很多技术文章相互参考,有些代码自然也直接复制粘贴使用
- Headless Chrome自然也是这样,一些不好的编程习惯也被错误地传播
于是有了本文,以及一些个人的思考。
思考 🤔
首先,在Google搜索Headless Chrome相关的技术文章,会跳出来官方文档以及各种技术文章:
(关键词顺序反了,不过不影响 XD )
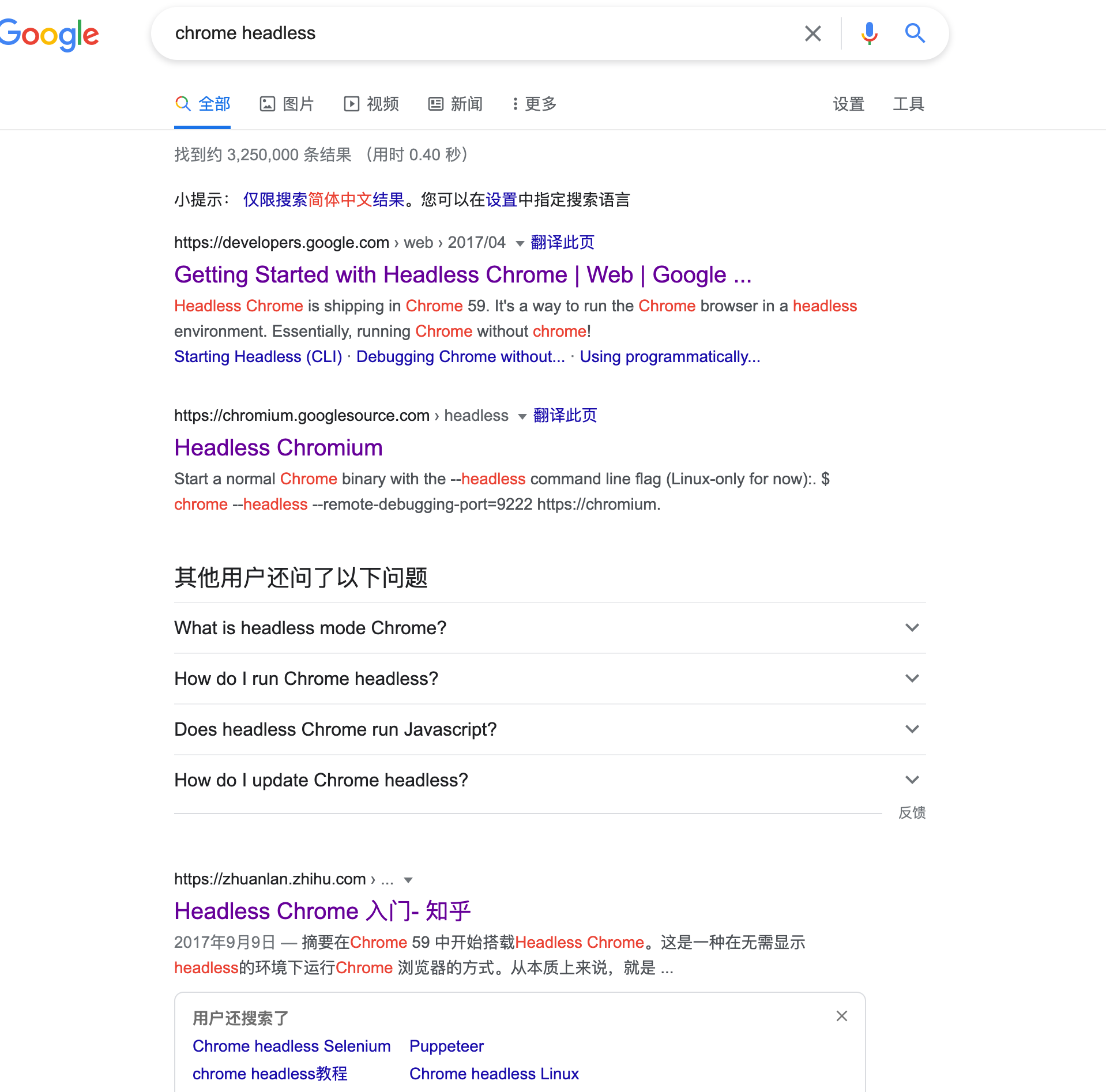
Headless Chrome其实就是从命令行启动Chrome,传递了--headless的参数,那么对于Chrome来说,有很多参数,但是有那么几个参数非常危险,比如 : --no-sandbox,--disable-web-security,以及开启调试端口…
在看了很多网上的文章后,我发现有不少代码是重复的(关键逻辑),比如这篇:

对于错误的参数也是一样的,比如不约而同地关闭sandbox:
1 | const browser = await puppeteer.launch( |
或者调试端口不是 9222就是9229这类情况。 这里其实有几个问题:
- 我使用的参数是什么意思?
- 这些参数对我的程序有什么影响?
- 这些参数安全吗?
- 什么情况下我可以用,什么情况下不能使用?
如果搞不清楚,对于只是个人学习来说搞个demo那倒还好,如果说是用于实际项目,比如写预览服务,爬虫等项目,还是直接使用了这些危险的参数那就太危险了。
- 线上环境要求稳定,不一定是最新版本node,即不一定是最新版本Chrome
- 危险的参数(比如
--disable-web-security),没有开启沙箱,开了调试端口等
老版本Chrome + NOSANDBOX = RCE 🤔
至此,我认为可以搞个Demo验证一下这个攻击思路是否可行。
Demo
Pages
这里直接扒了xlab某次安全推送,然后在本地跑起来,假装是一个目标网页:
下面搞两个场景吧,第一个是预览,简化一下,截图好了;第二个是爬虫,爬取这网页上的信息。
Demo1 : 预览
预览的场景有很多,比如常见的IM中,发送的URL可能会被渲染成“卡片”,不同IM处理不一样,一般来说只有白名单才会这样。
我这边不会搞太复杂的东西,就直接用截图代替了,直接也从网上”东拼西凑“点代码:
1 | const puppeteer = require('puppeteer'); |
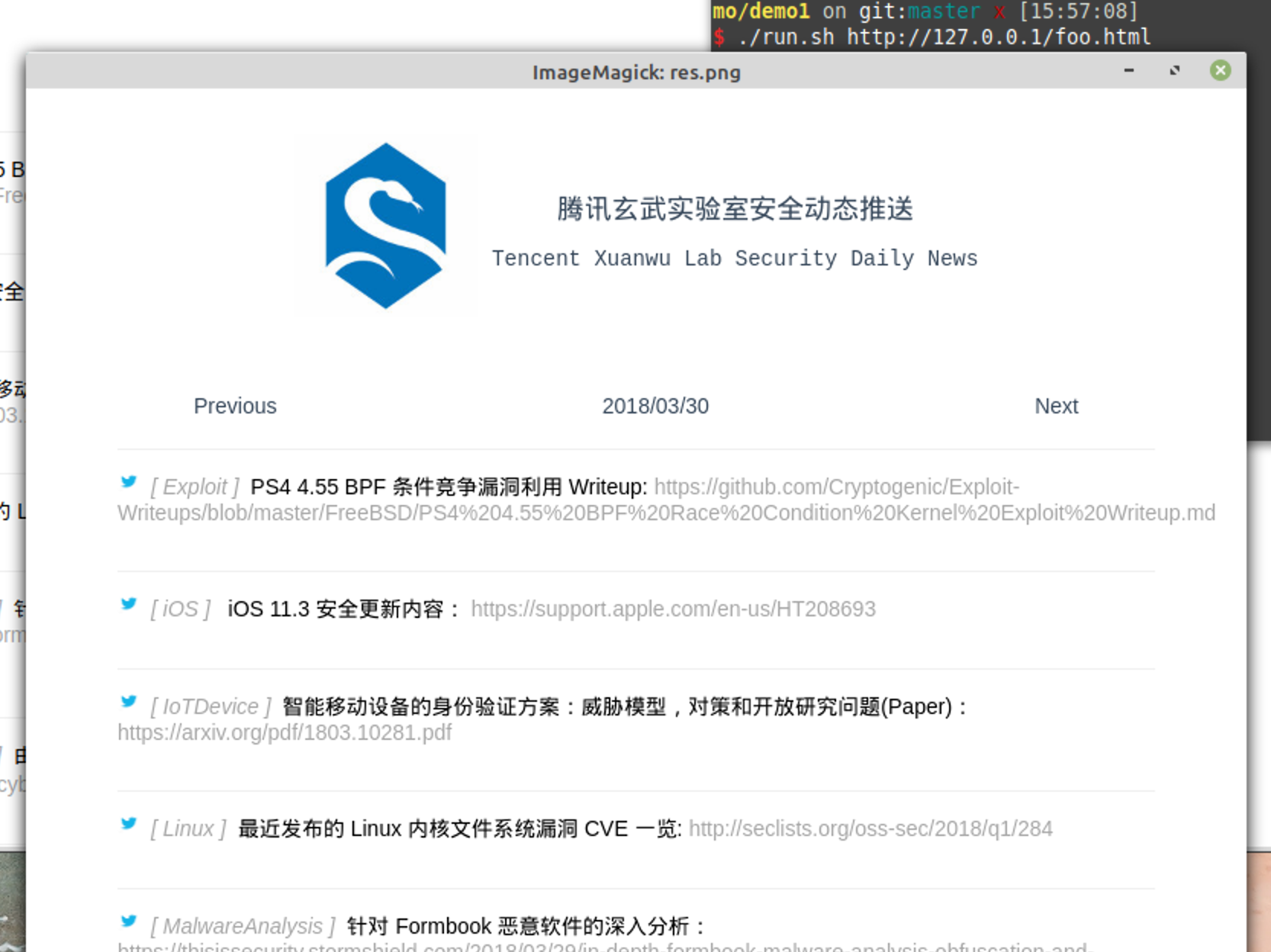
功能也比较简单,预览指定的网页,我这里搞得简单,直接截图然后保存,IM里那种卡片式不知道怎么搞,就没去尝试,不过也是个攻击面啦 🤣
跑一下Demo:
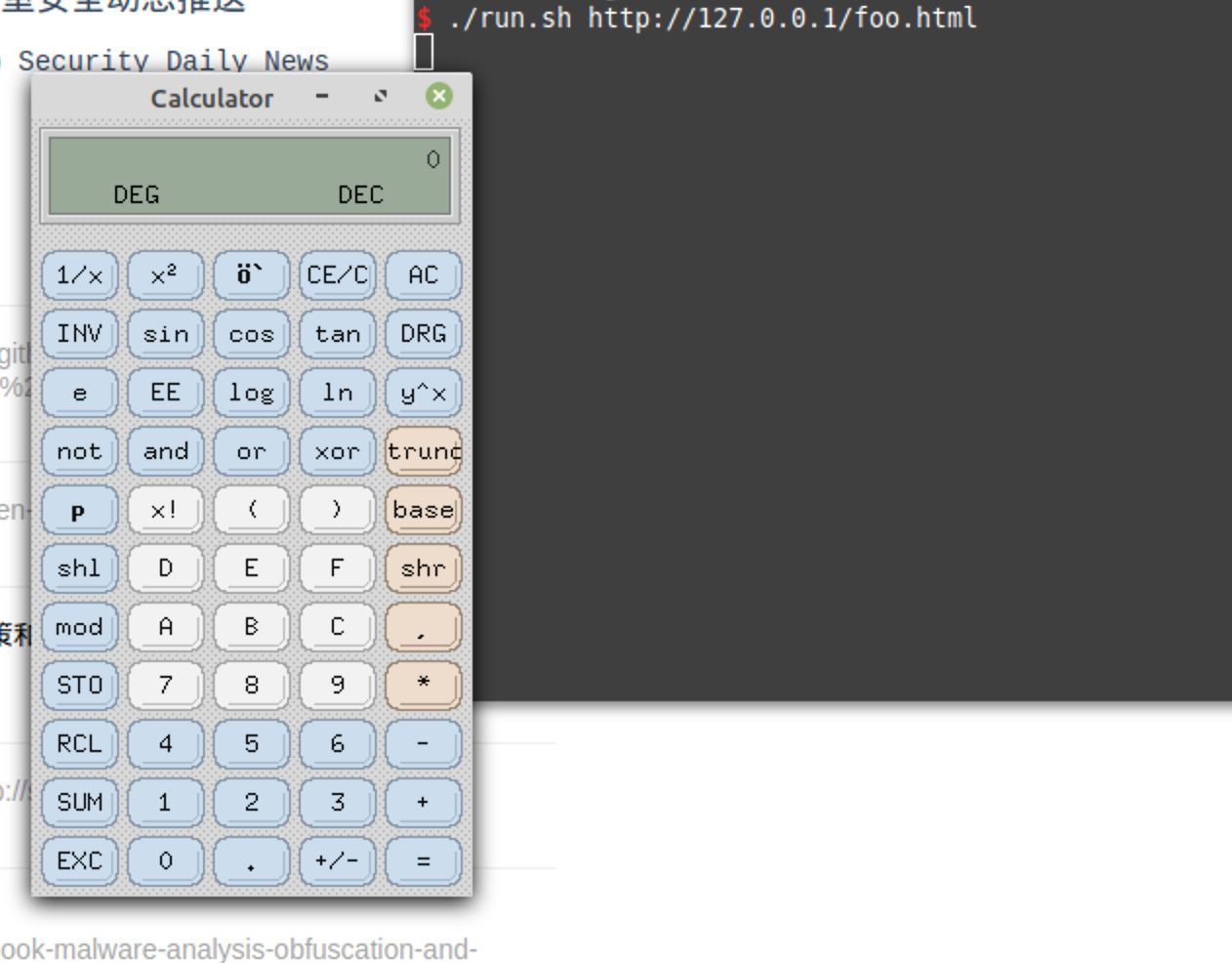
如果在页面里加载恶意的JS呢?
直接使用script 标签加载
加入js,使用js web worker加载
BOOM :
Demo2 : 爬虫
这里直接抄了https://www.anquanke.com/post/id/103350 里的代码:
1 | $ cat crawler.js |
预期行为:
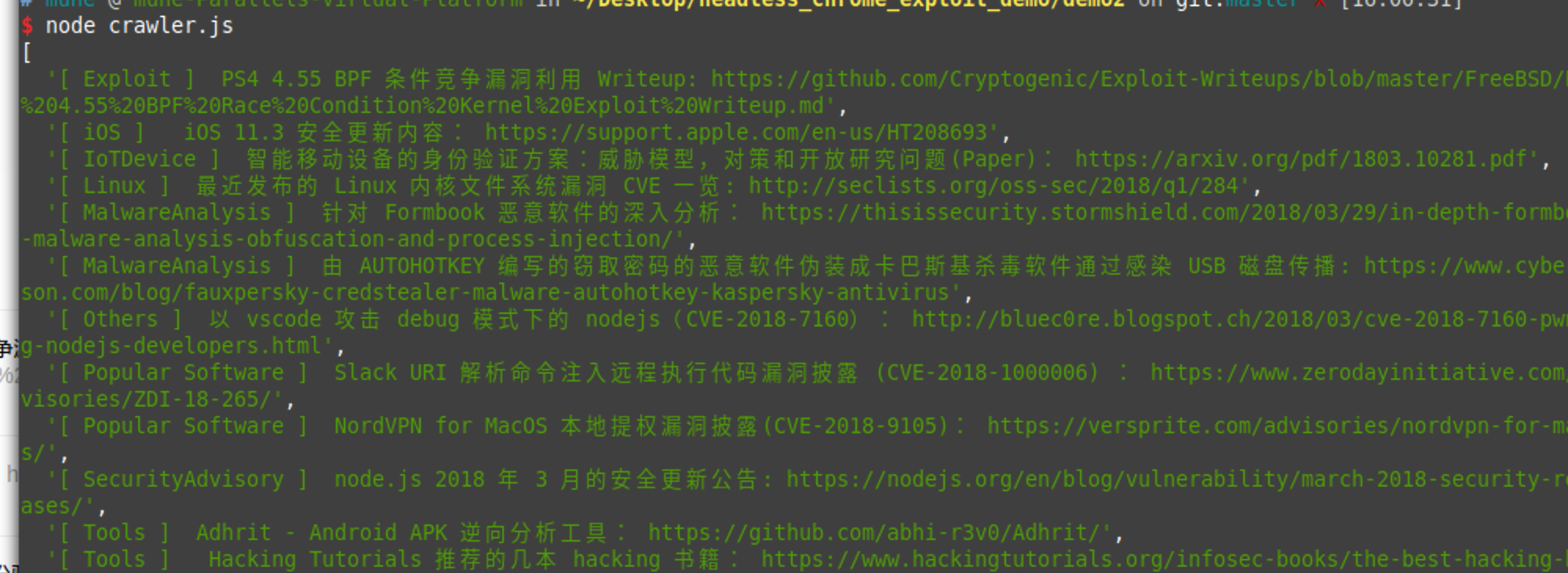
看起来不错 : )
加入恶意的JS之后:
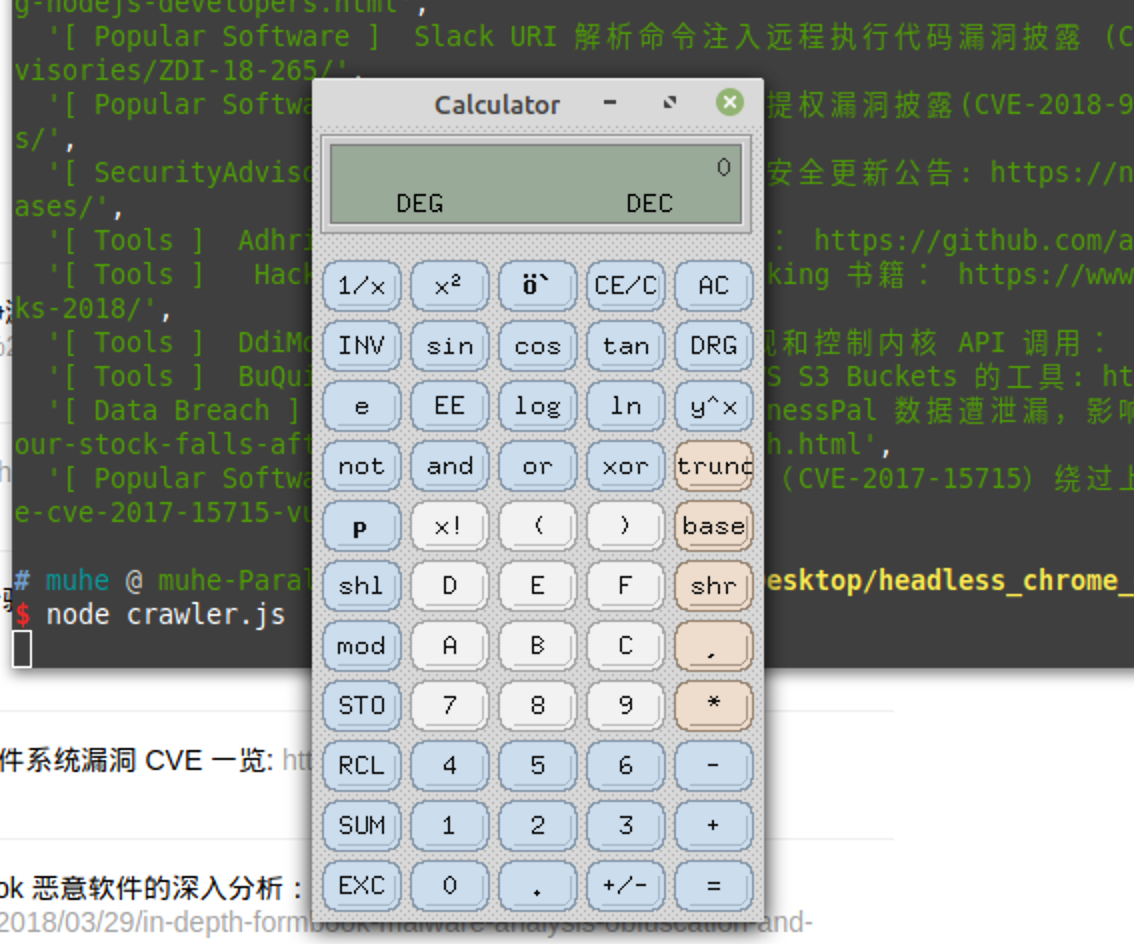
这里有个地方不完美,我本来尝试js web worker加载exp,想 爬虫正常工作,爬取到需要的内容,exp在后台跑,但是我发现要么时间不够我跑exp(需要爬虫停留的久一点),要么就exp跑了,但是内容没爬取到。这点我认为应该可以解决,如果有知道的前端大佬可以分享一下~
后记
那么是否存在这样一条攻击链,针对爬虫或者一些Headless Chrome的服务:
- 恶意构造页面,集成多个Exploit,覆盖大量Chrome版本,打进去就挖矿or种勒索?

最后还是建议以官方文档为准,写代码参考文档而不是从网上的技术文章里摘 : )
Demo & Exp
https://github.com/o0xmuhe/headless_chrome_demo